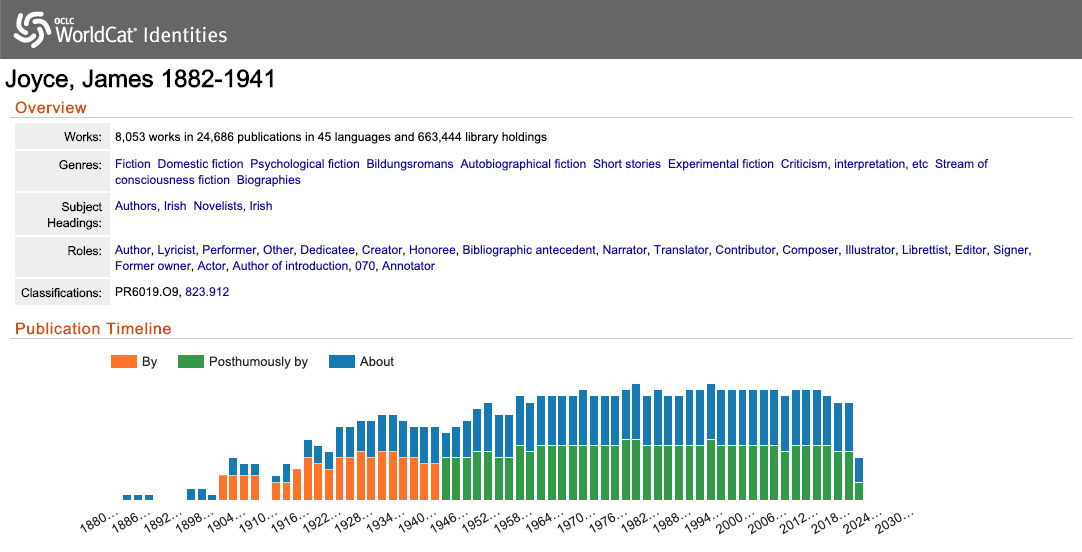
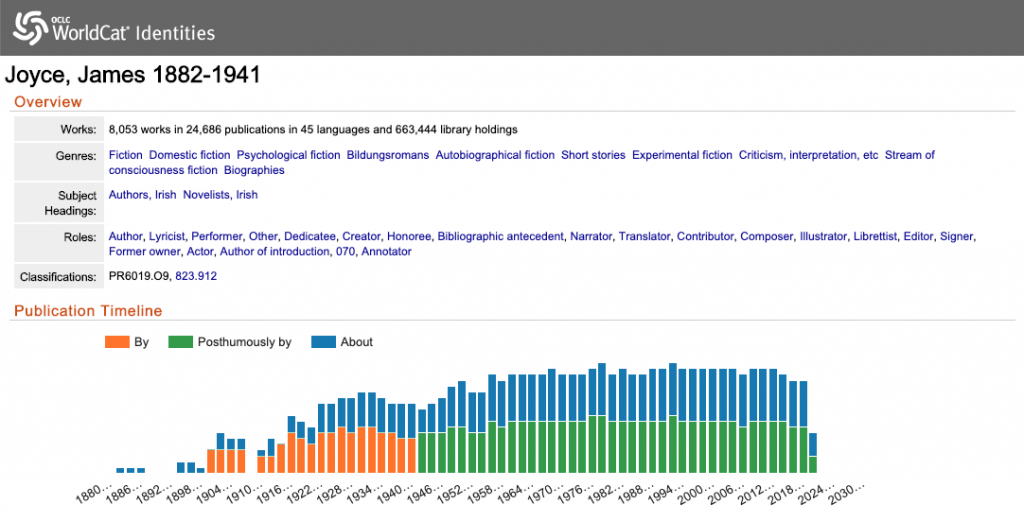
Earlier this year, I joined the team at the Centre for Manuscript Genetics, and started working on the project titled “James Joyce’s Unpublished Letters: A Digital Edition and Text-Genetic Study”. The project has the (unpublished) letters of James Joyce as its main object of interest, and it aims at creating a unique digital edition of the collection of letters, which would help explore Joyce’s writing habits, as well as his personal life and his role as a central figure within the modernist literary period.
The project will follow the already well-known and established standards introduced by the Text Encoding Initiative (TEI) for documenting and annotating the letters. This will ensure that our data will be understandable, integratable, and comparable with other projects that work with the same standards. At the same time, it will provide us with an initial document structure, which we will be able to expand on, if necessary.
Currently, all the metadata that we have gathered on the letters exists in a Microsoft Excel sheet. This sheet records some of the most typical information pertaining to a letter, such as the date, sender information, recipient information, repository where the letter is currently held, and so on. All of the entries in this spreadsheet will eventually have to end up in a well-structured TEI-XML file that describes that one specific letter. The process by which this transformation is to be carried out is still a topic of discussion, and will be the subject of a future blog entry. For the time being, we are interested in expanding our initial metadata collection by disambiguating and determining the most essential metadata fields necessary for conducting text-genetic research on an author such as James Joyce.
Some of the most essential pieces of information in a correspondence are those related to the date of the letter, the two ends of the correspondence (the sender and the recipient), and their geographic location. Although these attributes may seem to be straightforward at first, they require a lot of attention in order to be documented accurately.
Dates
Dates are indispensable in that they allow us to situate the letter within a historical timeline. They can help us link Joyce’s primary published works with the events he refers to in the letters. This can give us more insight into the mind of the author at a certain point in time, and it can shed light on the literary and stylistic choices he made in composing his oeuvre.
James Joyce did not always note down the date on his letters. Even when he did, he often left it incomplete (by indicating e.g. only the day of the week, or only the month), or he even wrote down the wrong date. The editors of the published volumes of letters did their best at dating these letters as precisely as possible, and their dates often contrast with one another. Generally, it is assumed that the more recent dating is the most precise, since new information about the letters surfaces from time to time. Our intention is to document all these different dates in order to be able to compare and contrast them with each other later on. That means that a single letter will have a metadata field for the date Joyce wrote himself on the letter, and a metadata field for a list of dates provided by the publications in which the letter had already appeared. In the case of an unpublished letter, the latter field will be empty. In both cases, however, we want to include a third field, which would be a single point in time (formatted as a day), and which would act as our own best guess, having taken into consideration Joyce’s own date, editors’ dates, and the temporal references found in the text of the letter and on the envelope. We want to have a precise date with consistent formatting (e.g. YYYY-MM-DD) associated with each letter in order to facilitate data filtering and querying once we start developing applications on top of this data. Our intention is to avoid grouping different incomparable data types (“early spring 1903” vs “1903-04-01”), and instead find a configuration, in which the data can be consistently expressed. A letter with uncertain single date could always be accompanied by additional entries specifying the absolute range in which the letter could have been composed (e.g. notBefore="1903-03-21" and notAfter="1903-04-21”). In the final application, the best-guess date will always be accompanied by all the other dates and ideally an explanatory note, in case the user wants to check the validity of the chosen date themselves.
Identities and Authority control
Since our project is concerned with the letters James Joyce wrote, the information about the sender should consistently be that about James Joyce himself, although it is not always easy to determine the authorship of the letter with absolute certainty. The information about the recipients is, of course, much more varied, and needs to be recorded in an efficient way. The way we plan to approach this issue is by supplying the plain names of the recipients with the URL references to their respective entries in online authority control catalogues. The reasoning behind this practice is the intention to point to an existing identity record, rather than creating a new catalogue from scratch, risking having duplicate entries for the same identity, or leaving the field without any authoritative pointers. Linking our data in such a manner will also allow us to make use of the already existing information associated with the named entity in that catalogue, and use the same to enrich our digital edition.
Geographical locations
The addresses of both Joyce and his interlocutor are often incomplete, uncertain or even omitted. At times, he provides the full address from which he is writing, including the street name, the postal code, and even the name of the hotel, in which he is staying. At other times, he only indicates the name of the city. Our initial approach would be similar to that described in the previous section. The transcription on the letter would include the the geographical information as it is indicated by the author, whether they be complete or not. In the metadata part of the letter, we would use the information found in the letter and in Joyce’s biography to pinpoint a complete address, and supply it also with a reference to a geographical authority file. The latter would include additional information, such as the geographical coordinates, which we could use for displaying Joyce’s network of correspondences on a map, for example.
Data types and validation
Apart from the three most salient problematic fields described above, we plan on documenting a variety of other information, such as the languages used in the letter, the repository where the letter is currently situated, the medium used to write the letter, and so on. These seem to be somewhat easier to determine, as they require less interpretative effort or background research. However, they need to comply to certain rules that are common to all the metadata documented, including the three described above. Each field needs to belong to a certain data type, and conform to a consistent formatting. The date field, for example, will either have to be entered as a number or a string. For the sake of human readability, we might want to document it as a string with the following formatting: YYYY-MM-DD (e.g. 1904-06-03). Additional decisions will have to be made in regard to the letters with unspecified day of the month (such as Joyce’s letter to Henrik Ibsen, which Joyce dates “March 1901”). Having consistent metadata fields will ensure that applications built on top of our data will have to do less processing and error checks in order to obtain what they expected from the data.
We are currently also in the process of deciding which metadata fields should contain one unique value, and which ones should be expandable and accept a list of values. A free list of values would make sense in the case of the ‘Languages used’ field, for instance, as there is not a predefined list of the combination of languages Joyce might have used. In contrast, the predefined list would make sense for documenting the repository where the letter is currently held, since it can only be in one place at the time, rather than at a list of places.
Once our data is well structured and consistent, we will be able to start building experimental applications with an initial sample. We put a lot of emphasis on structured data, as it is the fundamental basis on which the digital edition will exist. Other specialised visualisation and filter applications drawing on this collection of letters will likewise be dependant on the quality of the gathered data.
These are the most notable challenges that we have faced so far what collecting the metadata is concerned. The next steps involve deciding how the metadata should be documented, and applying the same to a first selection of data. After an initial sample of metadata has been collected, we will be able to provide a more elaborate review of our practices, their success, or lack thereof.
Until then.
Leave a Reply